|
|
|
Introduction
An archiphone is an
organ tuned to 31-tone equal temperament ("normal" western music
uses 12-tone equal temperament). The primary goal
was to build a working Archiphone Synthesizer (keyboard and
sounds). After that was accomplished, I used the
remaining time to work on some random features that one might
expect of a modern synthesizer (such as saving and loading
songs to be played automatically).
High Level Design
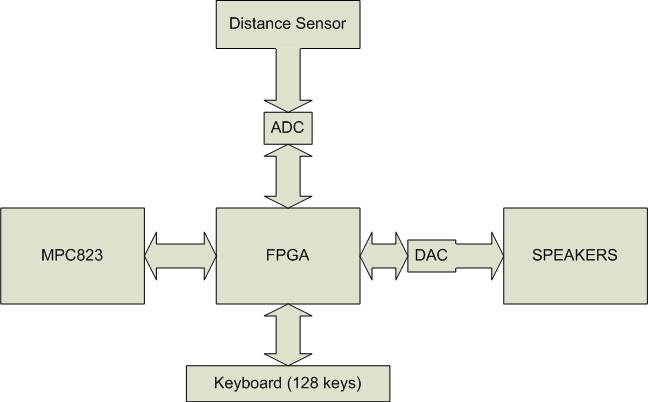
The
high level functions are as follows:
Keyboard polling
Distance sensor reading
Sound Generation
Saving / Loading
key presses (for automatic play back)
Overall, a very
simple setup. Every aspect of the design serves to drive
the speakers as the final output of the system. The keyboard
data controlls what notes are played, while the sensor data and processor
interaction modulate the final output sounds.
Member Task
Distribution
I was the only person in the
group, so...
Hardware Design
KEYBOARDS
Simple concept, annoyingly messy wiring. A key can
be checked for a press by tying the row to a voltage
and checking the column for the same voltage (key
press completes the corresponding row-column circuit). Used multiplexers and decoders
to poll each key. The result of each poll was stored in
a set of registers for any time
access by the other software/hardware components.
SPEAKERS
Very simple to use.
DAC---->LPF----->Speakers. Acceptable range for
the sounds I wanted (below around 300Hz the sound was very
choppy). The low pass filter was only used to remove
extremely high frequency interference. The resolution
of the reference waveform in the final
implementation was high enough that
the audio signal didn't need a
low pass filter for reconstruction purposes.
DISTANCE SENSOR
Used as a "whammy bar" of
sorts to vary the frequency of the notes that are
played. The value obtained was used to vary the clock speed used for the sound generation modules,
thus directly modulating the frequency played.
DISPLAY / LIGHTS
Abandoned due to physical constraints.
PEDALS
Abandoned due to time constraints.
SOUND GENERATION
The main idea is to build an audio signal using a
single reference waveform. An individual note is made
by sending the reference waveform to the speakers at the
appropriate speed (same shape, but tunable frequency).
Multiple notes can be played at once by adding all the
individual notes together before sending the result to the
speakers.
Each note had a predetermined speed (in the form of a
clock division constant used with the clock provided to the
sound generation module), a position counter, and an
enable. The position counter would cycle through the
waveform, moving on the rising edge of it's custom divided
clock. The position counter was reset and held at 0
when enable was low, stopping that note.
Software
Design
SOUND GENERATION
Follows the same idea
as with the hardware version of sound generation. For
simplicity and compiler limitations, 31 reference
waveforms were used (one for each note, the next octave
always being twice the current frequency).
The benefits to using
software for the sound generation would be a more efficient
use of space and a more straight forward way to
manipulate the sounds before playing it through the speakers. Ultimately, this
would be the ideal way to do
things.
Initially, the interrupt
handler for the sound generation took too long to complete
(nyquist rate of notes could not be achieved). This is
what prompted the move to a hardware
implementation. A data buffer was another solution, and one that
would have ended up working much better. Unfortunately, I stuck with
the hardware version and ran out of
time.
TIMERS
The timer speed was never
an issue (it was the execution time of the interrupt handler
that caused problems).
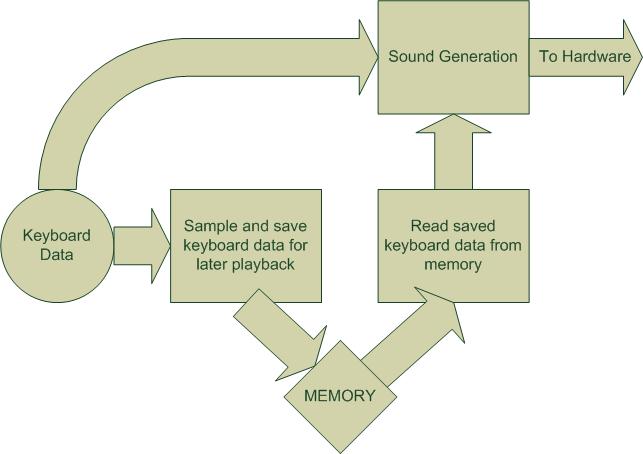
SAVING AND
LOADING SONGS
By storing
information about what keys are pressed when,
it is possible to record a song and play it
back later. To conserve memory, only changes in the keyboard (key
press, key release) were saved, and periods of no
change were compressed to a single number indicating for
how many cycles nothing changed. The format of the saved
data was like xml, so reading
the data is very simple.
All of this was
coded in assembly, but I never had the chance to give it a
full test with the hardware (couldn't fit any more registers
in the FPGA). The sampling rate is tuneable, but there
were no concerns with precision as the keyboard inputs are
extremely slow compared to the processor speed.
Results of the Design
Size and speed were ever
present problems in this project. Without using a data
buffer, the processor speed was too slow to play the sounds I
needed. When I moved the sound wave generation to
hardware, it was a constant struggle to get the design to fit
in the FPGA. I created about ten different
versions of the basic system. Also, use of the
distance sensor while playing sounds made the audio
choppy. With more time, an external register could have
been used so that the sound didn't need to be interrupted
whenever the ADC was used.
The large scale of
this project also created problems in the physical
hardware design. A simple character display was overly complicated
for just displaying what keys were being pressed.
The use of LEDs was considered in depth, but I
didn't have enough pins for a straight forward solution.
Another potential solution required an op-amp and a transistor for each key (all 128 of
them), so I moved on...
In the end, I had to
compromise complete system integration in order to
demonstrate all the parts. Additionally, many of the
extra synthesizer functions never got to be
tested with the actual hardware.
If given more
time (or with the help of some more group members),
I would explore generating the sounds in software using
a buffer to overcome the speed issues. With a working software sound generation, theremaining features would
be very straightforward to add in.
Conclusions
Had I known more about the hardware limitations I
would encounter, I would have spent more time making
the sound generation work in software. While I was
able to get the basics working using only hardware, there was
no room left for anything extra. Spending the same
sort of time with the software issues would have resulted in
a more extendable system in the end.
As for more power, I am
confident that my current implementation would have worked as
I had hoped if I didn't have to deal with the hardware and
software limitations. However, most of my problems could
have been solved with a data buffer and possibly saving the
reference data in SRAM to conserve space and increase
speed. Oh well, I had fun, and accomplished my primary
project goals very early
on. | |
|