Assistant Professor
Computer Science and Engineering
2260 Hayward St.
University of Michigan
Ann Arbor, MI 48109-2121
Office: 4709 Beyster
Phone: 734-764-9418
Fax: 734-763-8094
Send email to me at michjc, found at umich dot edu
Building and Searching a Structured Web Database
This material describes work supported by the National Science Foundation under Grant No. IIS 1054913, Building and Searching a Structured Web Database. This document describes work done in the third year of the grant, 2013-2014. To see the version of this document that covers year 1 (from June, 2012), click here. To see the version of this document that covers year 2 (from June, 2013), click here. A portion of this work has also been supported by an award by the Dow Chemical Company. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.| Award Number | IIS 1054913 |
| Duration | Five years |
| Award Title | CAREER: Building and Searching a Structured Web Database |
| PI | Michael Cafarella |
| Students | Shirley Zhe Chen, Dolan Antenucci, Jun Chen, Guan Wang, Bochun Zhang. |
| Collaborators | Prof. Eytan Adar, for the work with scientific diagrams in year 1. Professors Margaret Levenstein, Matthew Shapiro, Christopher Re for the work on nowcasting in years 2 and 3 | .
| Project Goals |
Our initial research proposal focused on the following work for Year 3:
Effort A is complete. Our spreadsheet-centric extraction work incorporated a cost model for human supervision in connection to information extraction tasks. In particular, by building an extractor that strategically reuses human annotated data, we were able to reduce the required amount of human effort by 69%. Effort B is complete. Our deployed spreadsheet/database search system implements not just relevance ranking for text search, but also performs join-suggestion for deeper user queries. A video of this system is available online at http://www.eecs.umich.edu/db/sheets/index.html. The source code for this system is being prepared for general release; a sizeable portion of it is now available. Effort C is being planned for classes later in this year. In addition to the above efforts, we have used a small portion of these funds to start work on a form of “somewhat structured” data not present in the original proposal: short texts from services such as Twitter. Certain examples of such texts can be used for nowcasting applications where textual activity is used to characterize real-world phenomena. For example, if there is an increase in the quantity of people who mention, “I lost my job,” then the real-world unemployment rate may be going up. The nowcasting application area has received broad interest but academic analysis so far has been fairly minimal. Our work treats social media text as a form of “somewhat structured” data that varies over time instead of spatially like spreadsheets. We have collaborated with economists in an effort to make this work applicable to practicing real social scientists. Our work in this area has already yielded some good results, described in more detail in the Findings section. In particular, our work includes a WebDB 2013 paper, a VLDB 2013 demo paper, a KDD 2014 paper, an NBER economics paper, and a working website: econprediction.eecs.umich.edu.
|
| Research Challenges and Results |
Information ExtractionSpreadsheets are an important, but often overlooked, part of data management. They do not contain a huge volume of data as measured in sheer number of bytes, but are very important nonetheless. First, spreadsheets are the result of many human beings’ hard work and receive more direct attention than most other data: the information they contain was very expensive to obtain. Second, spreadsheets often hold data available nowhere else, so data systems must either process them or learn to live without.Of course, any metadata in a spreadsheet is implicit, so they are unable to exploit the large number of tools designed for the relational model. In particular, integration among spreadsheets is a serious challenge. Spreadsheet software offers no easy way to combine information from multiple sources, even though organizations and some individuals now have spreadsheet collections that span decades. Our system automatically transforms spreadsheets into their relational equivalent so they can be queried as if the data were simply contained in a traditional database. In case of errors, users can manually repair the extracted data. Work for the past year focused on extraction of brittle metadata via effective manual repair. Many previous information extraction tasks have focused on populating a database that has already been designed; consider using a corpus of Web text to find pairs of company names and their headquarters locations. Recovering relational data from spreadsheets is quite different, because the spreadsheet includes the database design itself. Even small extraction errors when processing metadata can yield large numbers of errors in the output database. As a result, human beings must manually review and repair the automated extractor’s output, but doing so creates a large burden on the user. We have built a spreadsheet extraction system that requires explicit manual review of all results. This review-and-repair stage is necessary because the metadata extraction associated with obtaining a novel relation is very brittle: even a single error can yield a database with many incorrect tuples. Thus, the system must provide 100% accuracy for most applications. As a result, the cost of a low-quality extractor is the amount of human labor it generates in the form of errors to be corrected. Our extraction system obtains a good, though imperfect, initial extraction result: it obtains an F1 score of between 81% and 92%, depending on the type of spreadsheet. This means a user must correct roughly 16 errors per spreadsheet, on average. Using the previous state-of-the-art, the user would have to correct almost 59 errors per spreadsheet, on average. However, the real contribution of our system is in efficiently and repeatedly exploiting the user’s repairs. We use a conditional random field model to tie together multiple extraction decisions that are linked together either by similar style or by shared data. By finding extraction decisions that “should” be similar to each other, we can amortize the user’s repair over many errors simultaneously. As a result, we can reduce the total number of necessary repairs by as much as 69%. We have built a demo system for the extractor that was presented at VLDB 2013. A video of this system is at http://www.eecs.umich.edu/db/sheets/index.html. We have also had a technical paper accepted for publication at KDD 2014. We are preparing the source code for this system for public release, and a portion of the code is already available. We have also received commercialization interest from one established firm and one startup company. More recently, we have started to explore other semi-structured extraction tasks outside of the spreadsheet area. In particular, we are investigating obtaining a structured version of loose online product descriptions, such as the textual region of Craigslist and Amazon.com posts.
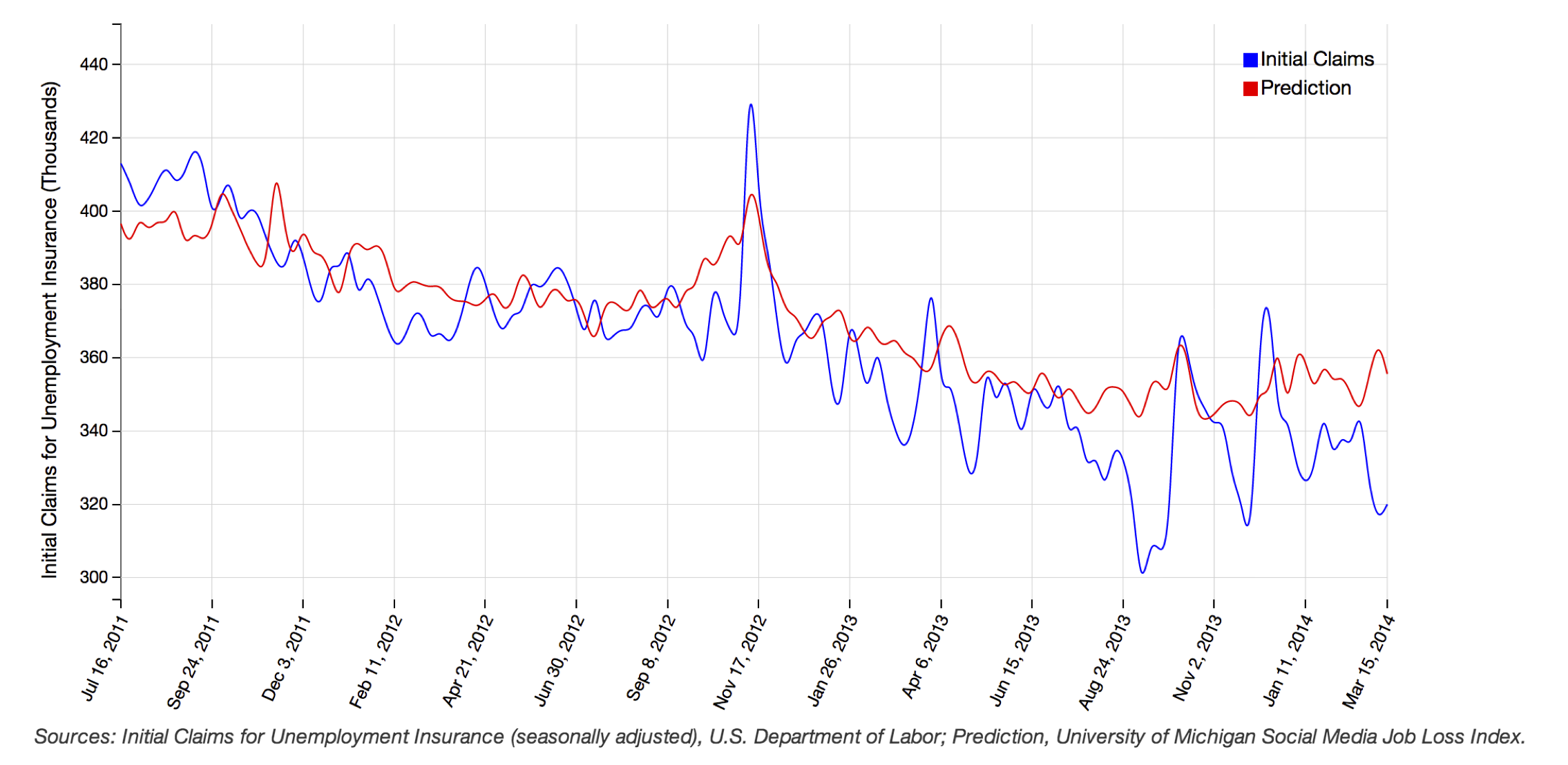
NowcastingIn addition to the spreadsheet work, a small amount of this grant was used to support investigation of time-varying structured texts such as Twitter streams, and their application to nowcasting applications. A particular problem in nowcasting is the choice of phrases that indicate a larger phenomenon. For example, repeated mentions of “I lost my job” may indicate a general rise in the unemployment rate. Given enough such signals (“I lost my job”, “I need a job”, etc) we can obtain time-varying signals from the social media source, then combine them into a prediction of the real-world unemployment rate.In addition to our own computational work, we have collaborated with economists on this project. Economics-Connected ResearchWe have published a National Bureau of Economic Research (NBER) paper entitled, “Using Social Media to Measure Labor Market Flows”. In that paper we found that social media derived information can be used to accurately predict the US government’s weekly initial unemployment insurance benefits claims number. Predictions from our social media-based mechanism are competitive with those from a panel of economists. When our index is combined with the economists’ predictions, the result is a predictor that is better than either one. There is also a version of this paper under submission to the American Economic Review. We have also built a standalone website that generates a weekly prediction based on the social media stream. It can be found at econprediction.eecs.umich.edu. Please see Figure 1, attached below.The blue line is the official governmental number about the number of weekly initial unemployment insurance claims. The red line is the estimate from our index, produced before the government releases its number. A few things to note:
Computer Science ResearchChoosing phrases to generate such an index may appear straightforward, but in fact humans are quite bad at choosing them; most suggestions from humans for a given phenomenon will be irrelevant. We would like to automate this procedure of choosing phrases for nowcasting. Traditional feature selection techniques would suggest using some known labeled data to evaluate candidate signals; in our case, we could rank all possible phrases by how well each correlates with the unemployment rate published by the US government.Unfortunately, the set of potential phrases is so large (more than a billion), and the amount of traditional data so small (just tens of observations for most phenomena), that standard feature selection techniques overfit the available data and yield terrible results. By avoiding use of the traditional dataset, and applying techniques that exploit statistics derived from the general Web corpus, we are able to build a useable synthetic feature selection mechanism. We tested it on six different social media phenomena, including unemployment, flu, retail sales, mortgage refinancing, and others. It can obtain results that are as good as, or in some cases slightly better than, those generated by a human being. We believe these results should help make nowcasting a real application rather than the strictly academic project it largely remains today. We have published an initial paper on the overfitting problem in the WebDB 2013 workshop. We also have an additional full research paper under preparation that should be complete in the next 6 weeks.
|
| Publications |
|
| Presentations |
|
| Images/Videos |
|
| Data |
A lot of our work throws off datasets that are suitable for use by other researchers. Here is the data we have collected so far.
|
| Demos |
|
| Software downloads | Our work so far involves fairly elaborate installations, so we have made the systems available for online use rather than download. |
| Patents | None |
| Broader Impacts | The PI discussed part of this work as part of a short class presented to high school students at Manchester High School in May, 2013. It had five components:
|
| Educational Material | None yet |
| Highlights and Press | Coverage of the economics work:
|
| Point of Contact | Michael Cafarella |
| Last Updated | May, 2014 |