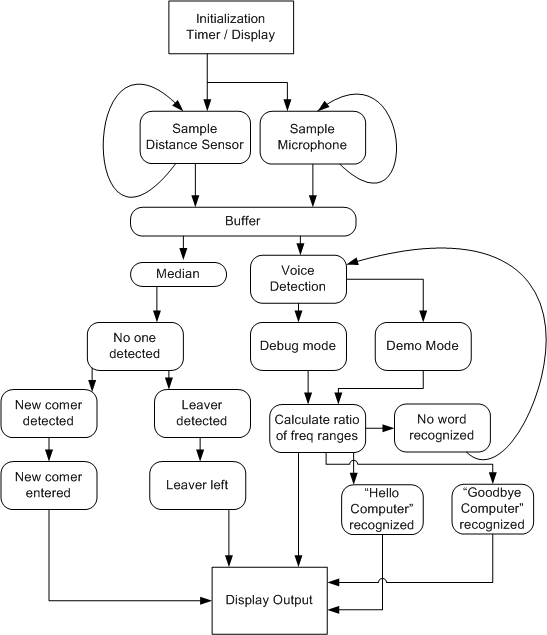
EECS 373 Winter 2007 ProjectvoiceBotOverview
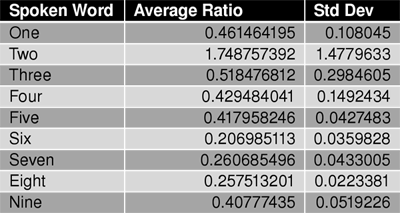
Our software is a combination of C and assembly code. The assembly code is used to initialize many of our devices, provide function level access to the memory mapped I/O hardware, and finally handle the interrupt that our distance sensor generates. Our C code functioned at a much higher level. The code there processed all of our sensor data and implemented our overall functionality. Distance Sensor Since we decided to implement the initiation pulse to the distance sensor in hardware, we only needed an interrupt to process the return pulse. The output of our edge detection logic was wired to an edge triggered interrupt. Our ISR for the distance sensor would read the register we implemented to determine if this was a rising or falling edge. Based on this value we knew if we had to start or stop the processors timer. On each falling edge the counter was reset, and the the current count was placed into a specific memory location. We had to do a lot data conditioning on the distance sensor data in order to determine if someone was approaching or departing our lab station. First, we only process a new data element if it was different than the last data element. Next, we insert this data element into a buffer, sort the buffer, and return the median value. This median value is then normalized on a 1 – 14 scale. Finally, the normalized data is inserted into another buffer and we use two flags to determine when someone is arriving or departing. LCD Display Since we implemented a bi-directional bus for our LCD display, our display write function implemented a spin lock on the LCD displays busy signal. This allowed us to avoid any sort of generic hardware or software based delay technique. Microphone For the microphone, we sample the counters into a buffer at the same rate as the distance sensor. In order to detect if a word is being said or not, the sampled values are put into a buffer. If the front and end values of the buffer are the same, then the values are passed along to the speech recognition algorithm and the buffer is cleared. Using the spoken numbers 1 through 9, we were able to characterize the pattern for some spoken numbers with very low standard deviation (Table 1). But due to the limitations of not having floating point arithmetic, our speech recognition algorithm would look at the smaller of the two zero crossing for either high or low frequency ranges and add the value to itself until it was greater than the larger zero crossing number. The number of times the smaller zero crossing value is added to itself and which frequency range is larger is used to characterize the word being processed. This means that many words fall into a wide category. Table 2 shows the lack of precision we get without floating point ratios.
Table 1 – Floating Point Zero Crossing Ratios of “1” to “9”
Table 2 – No Floating Point Zero Crossing Ratios
The speech recognition portion of the code has a debug mode and operational mode. The debug mode allowed us to see exactly which ratios certain words fall under. The operational mode took characteristics from the debug mode into account for characterizing speech and branching off to code for different behavior based on those characteristics. Created by Terry Dolan & Gary Wong |